Nf-core 워크플로우 마이그레이션 하기 (spatialvi)
2025년 5월 22일 현재 dev 버전 branch에서 테스트 되었습니다.
참고문서
마이그레이션을 위한 환경 구성
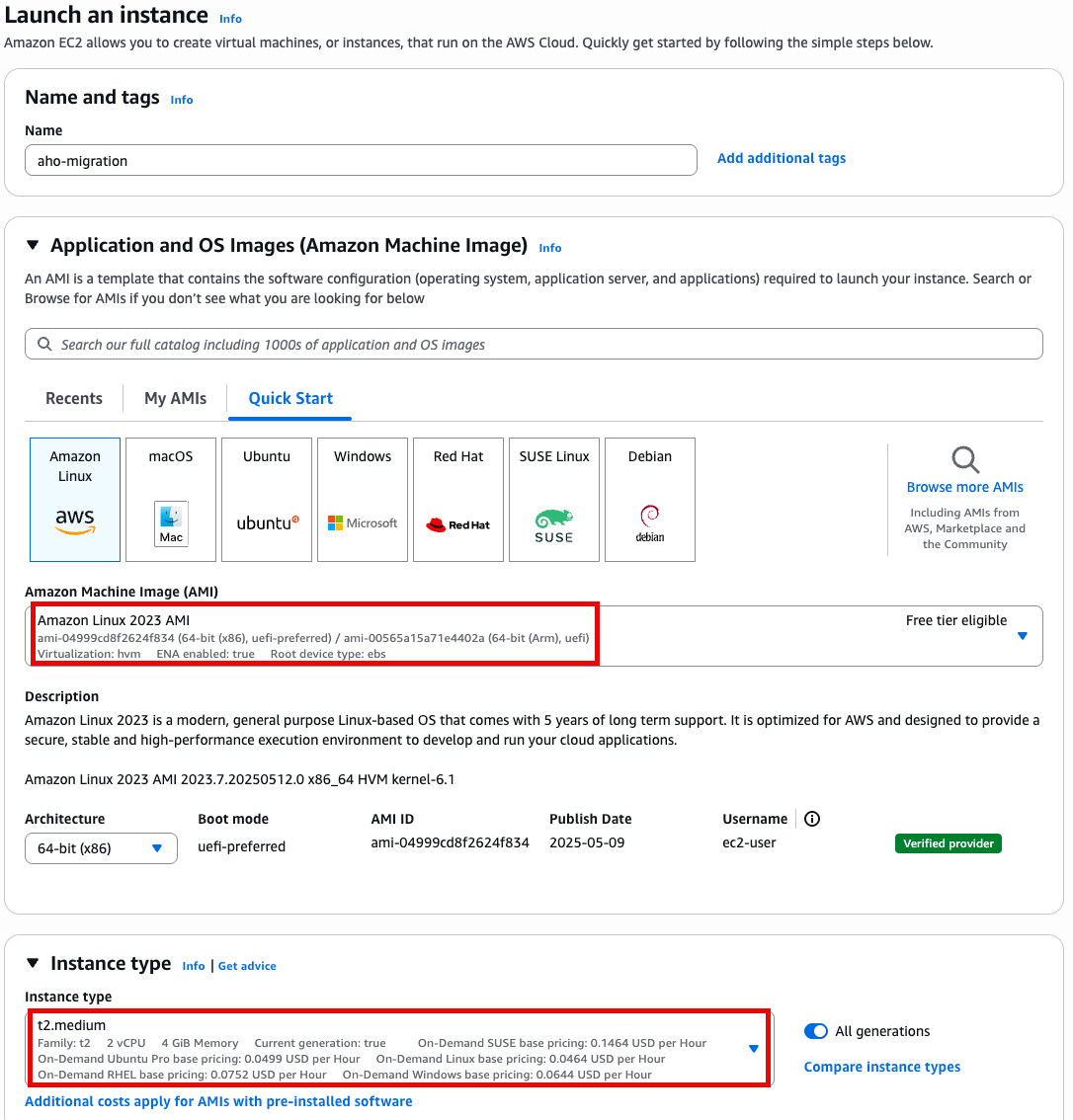
Step1 - Ec2 기반 환경 구성
Ec2기반이 아닌 CloudShell 기반으로도 세팅할 수 있습니다. (참고) 선호하는 환경에서 작업하세요.
- t2.medium
- Amazon linux 2023 AMI
- 64 bit x86
Specify instance type options
Generate key pairs
If you don't already have a key pair then select create keypair

Give the key pair a name and select the key pair type and format.
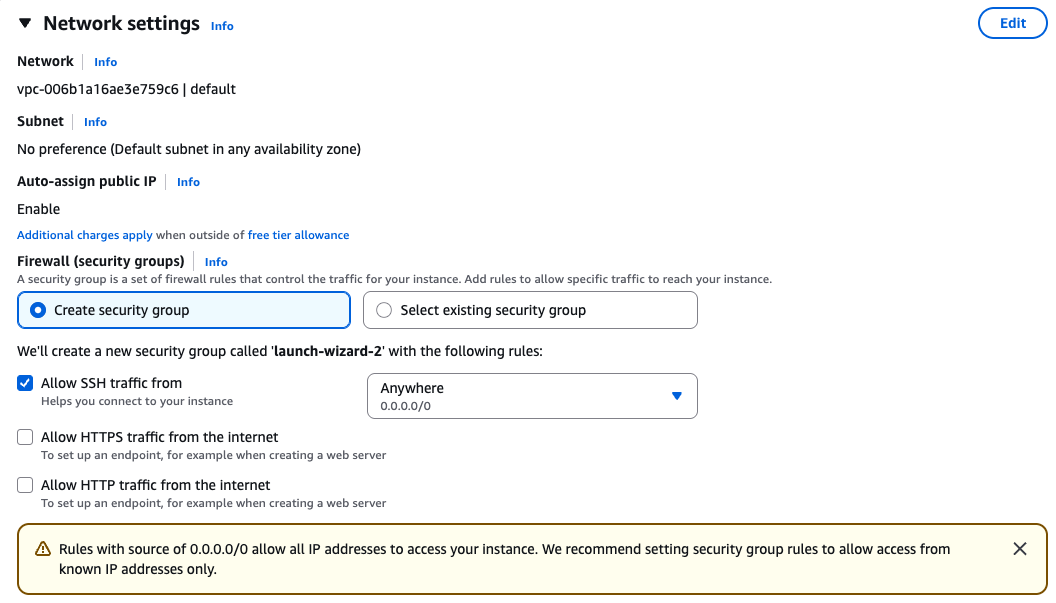
Security groups
Ensure that you have access to the instance via SSH.
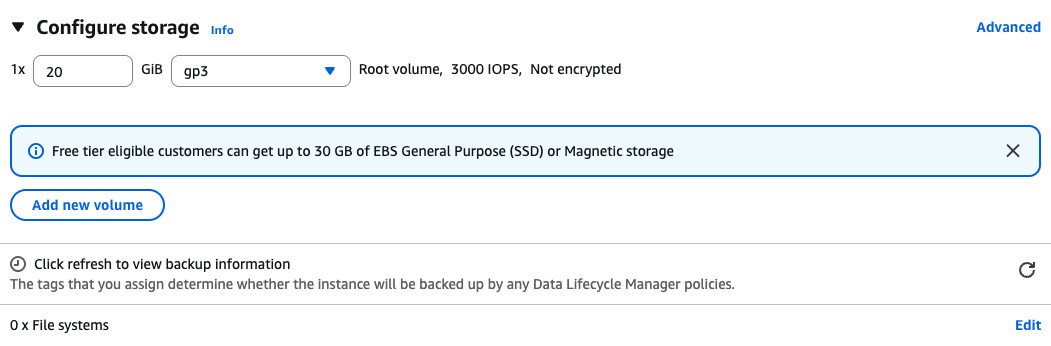
Storage
Create a root volume of 20GB
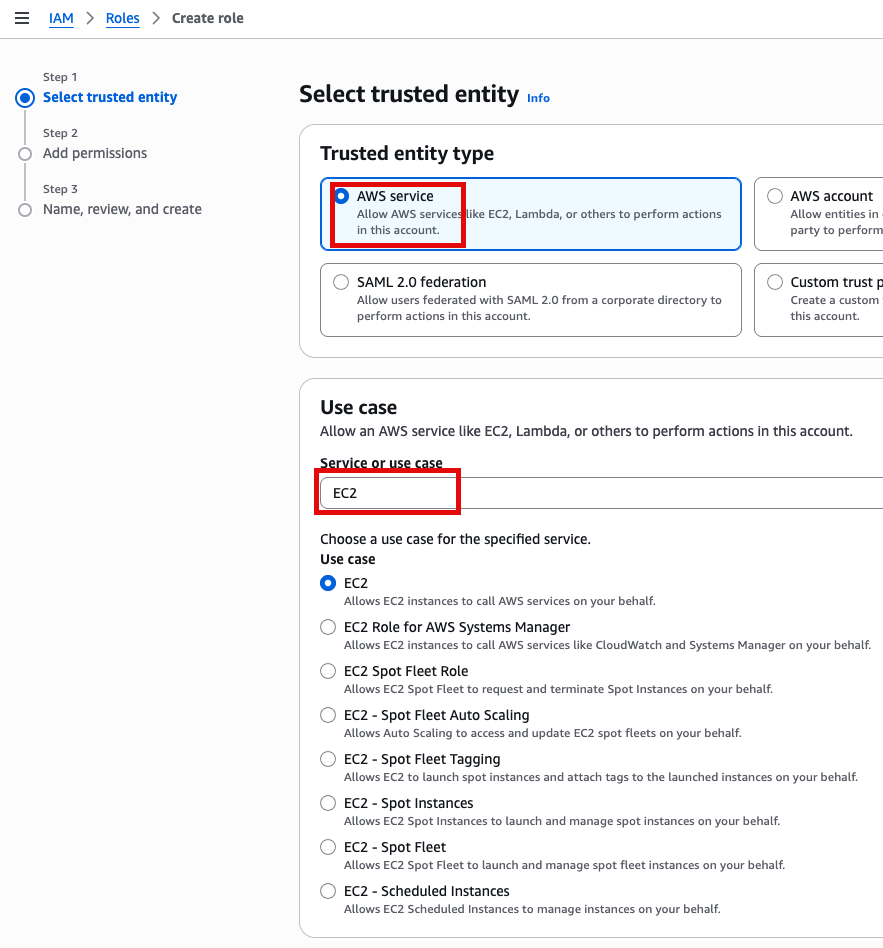
Instance Profile
We will create an IAM instance profile to allow administrator permissions for the EC2 instance, for the purpose of this workshop. However, in general, AWS security best practices recommendation is that you create an instance profile with least privilege. This configuration is not recommended in your own account, you should discuss organizational best-practices with your IT team to configure appropriate permissions.
Advanced Details 토글

IAM Instance profile에서 Create new IAM profile 선택

AWS service, EC2 선택
Add Permissions 화면에서 AdministratorAccess 추가(선택)
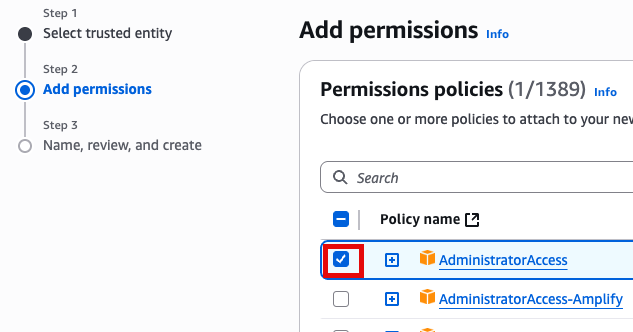
새로운 role name을 지정 (여기서는 EC2adminAccess라고 작성했음)
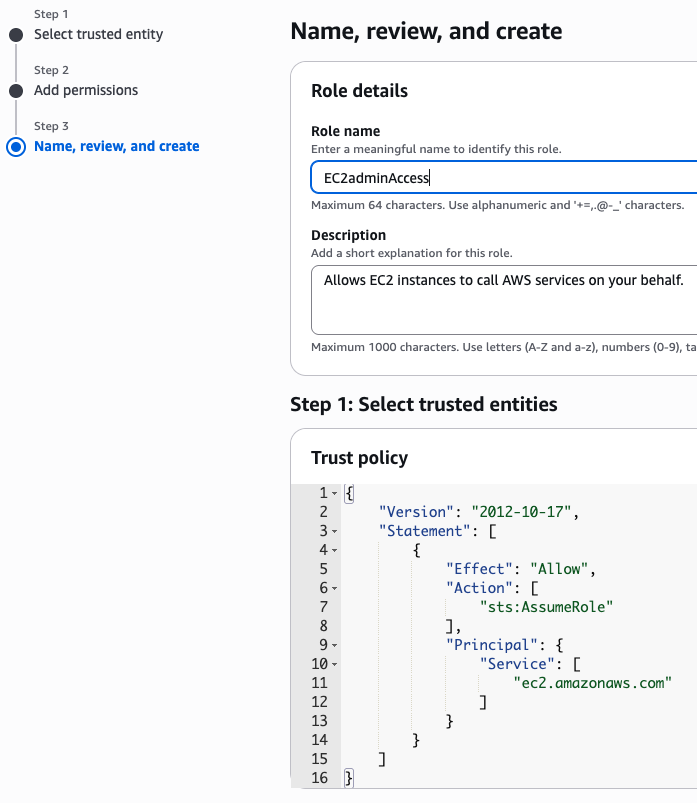
이제 EC2 instance 실행 화면으로 돌아가서 앞에서 만든 EC2adminAccess 선택

User Data
맨 아래의 User data 섹션에 내용 추가
#!/bin/bash
echo "Setting up NodeJS Environment"
curl https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
echo 'export NVM_DIR="/.nvm"' >> /home/ec2-user/.bashrc
echo '[ -s "$NVM_DIR/nvm.sh" ] && . "$NVM_DIR/nvm.sh" # This loads nvm' >> /home/ec2-user/.bashrc
# Dot source the files to ensure that variables are available within the current shell
. /.nvm/nvm.sh
. ~/.bashrc
nvm install --lts
python3 -m ensurepip --upgrade
pip3 install boto3
npm install -g aws-cdk
sudo yum -y install git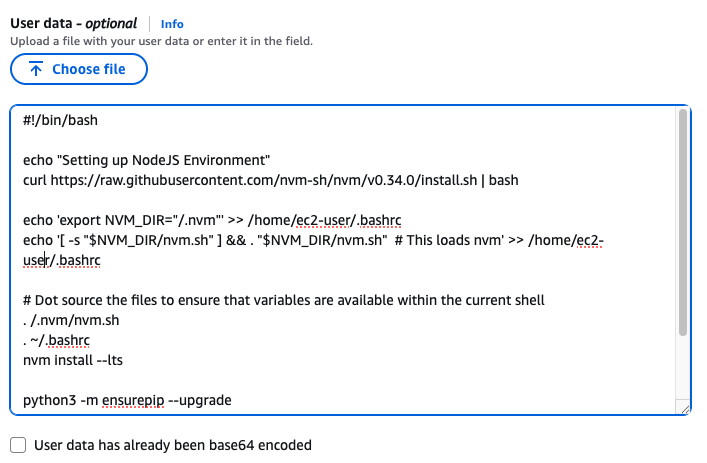
Launch instance 눌러서 인스턴스 실행
Step 2 - workflow migration code를 세팅하기
SSH 접속, 앞에서 만든 console로 접속합니다.

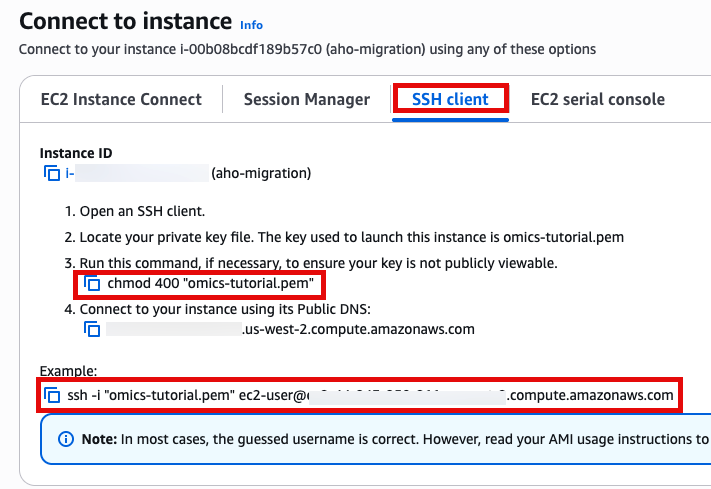
Use SSH to access the instance, you will need to ensure the key you created earlier is in the .ssh folder in your home directory and has the correct permissions(chmod 400). You will need replace ec2-user@10.11.12.123 with the IP address of your instance. This can be found in the EC2 management console.
ssh -i .ssh/omics-tutorial.pem ec2-user@10.11.12.123Get the region using the ec2-metadata command. This handy oneliner stores it as a variable
REGION=$(ec2-metadata --availability-zone | sed 's/placement: \(.*\).$/\1/')Get the account number (if you don't already know it)
ACCOUNT_NUMBER=$(aws sts get-caller-identity --query 'Account' --output text)Bootstraping
Now you can bootstrap cdk replacing ACCOUNT-NUMBER with your account number nad using the $REGION variable created earlier.
cdk bootstrap aws://$ACCOUNT_NUMBER/$REGIONDownload the workflow migration code
This step downloads the code which is used to migrate the workflow into AWS HealthOmics Workflows
cd ~
git clone https://github.com/aws-samples/amazon-ecr-helper-for-aws-healthomics.git
git clone https://github.com/aws-samples/aws-healthomics-tutorials.git
cd amazon-ecr-helper-for-aws-healthomics
Install and deploy the code.
npm install
cdk deploy --all프로젝트 셋업
이제 원하는 nf-core의 워크플로우를 HealthOmics private workflow에 마이그레이션을 하기 위해 다음 과정이 필요합니다.
- Cloning a workflow from nf-core
- Generating artifacts for migration
- Privatizing containers by migrating them to your private Amazon ECR
버킷 생성 및 Bash 환경변수 선언
export yourbucket="your-bucket-name"
export your_account_id="your-account-id" #ACCOUNT_NUMBER
export region="your-region"
export workflow_name="your-workflow-name"
export omics_role_name="your_omics_rolename"
# if not exist the bucket, let's create.
#aws s3 mb $yourbucketClone nf-core repository that you want to migrate
cd ~
git clone https://github.com/nf-core/spatialvi.gitDocker Image Manifest의 생성
cp /home/workshop/amazon-ecr-helper-for-aws-healthomics/lib/lambda/parse-image-uri/public_registry_properties.json namespace.config준비된 namespace.config파일의 내용은 다음과 같습니다.

This file will be used as one of the inputs for the inspect_nf.py script. This script parses the entire nextflow workflow project and identifies all public docker images across all the tools and generates a manifest which will be passed as an input to the migration tool.
inspect_nf.py 를 실행합니다.
python3 aws-healthomics-tutorials/utils/scripts/inspect_nf.py \
--output-manifest-file spatialvi_dev_docker_images_manifest.json \
-n namespace.config \
--output-config-file omics.config \
--region $region \
~/spatialvi/
생성되는 두 개의 출력은 spatialvi_dev_docker_images_manifest.json 과 omics.config입니다.
spatialvi_dev_docker_images_manifest.json 파일은 예를들어 다음과 같은 모습이어야 합니다:
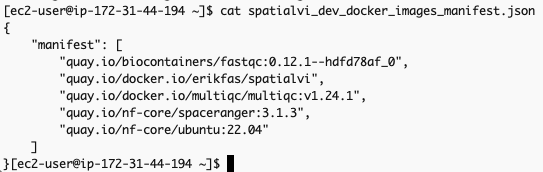
해당 파일의 내용을 다음과 같이 수정합니다.
{
"manifest": [
"quay.io/biocontainers/fastqc:0.12.1--hdfd78af_0",
"erikfas/spatialvi:latest",
"multiqc/multiqc:v1.24.1",
"cumulusprod/spaceranger:3.1.3",
"ubuntu:22.04"
]
}The omics.config output file is also generated, which needs to be added to the nextflow workflow project. The purpose of this config is to inform nextflow to use the ECR docker image locations instead of the ones specified in the nextflow project code. The omics.config should look like this:
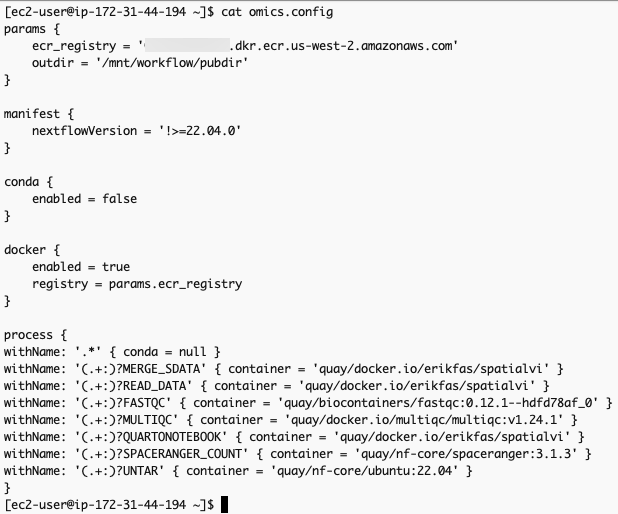
omics.config 내용 중 process에 정의된 내용도 아래와 같이 변경합니다.
cpprocess ~/amazon-ecr-helper-for-aws-healthomics/lib/lambda/parse-image-uri/public_registry_properties.json{
namespace.configwithName: '.*' { conda = null }
withName: '(.+:)?MERGE_SDATA' { container = 'erikfas/spatialvi' }
withName: '(.+:)?READ_DATA' { container = 'erikfas/spatialvi' }
withName: '(.+:)?FASTQC' { container = 'quay/biocontainers/fastqc:0.12.1--hdfd78af_0' }
withName: '(.+:)?MULTIQC' { container = 'multiqc/multiqc:v1.24.1' }
withName: '(.+:)?QUARTONOTEBOOK' { container = 'erikfas/spatialvi' }
withName: '(.+:)?SPACERANGER_COUNT' { container = 'quay/nf-core/spaceranger:3.1.3' }
withName: '(.+:)?UNTAR' { container = 'quay/nf-core/ubuntu:22.04' }
}컨테이너 사설화 (into Amazon ECR)
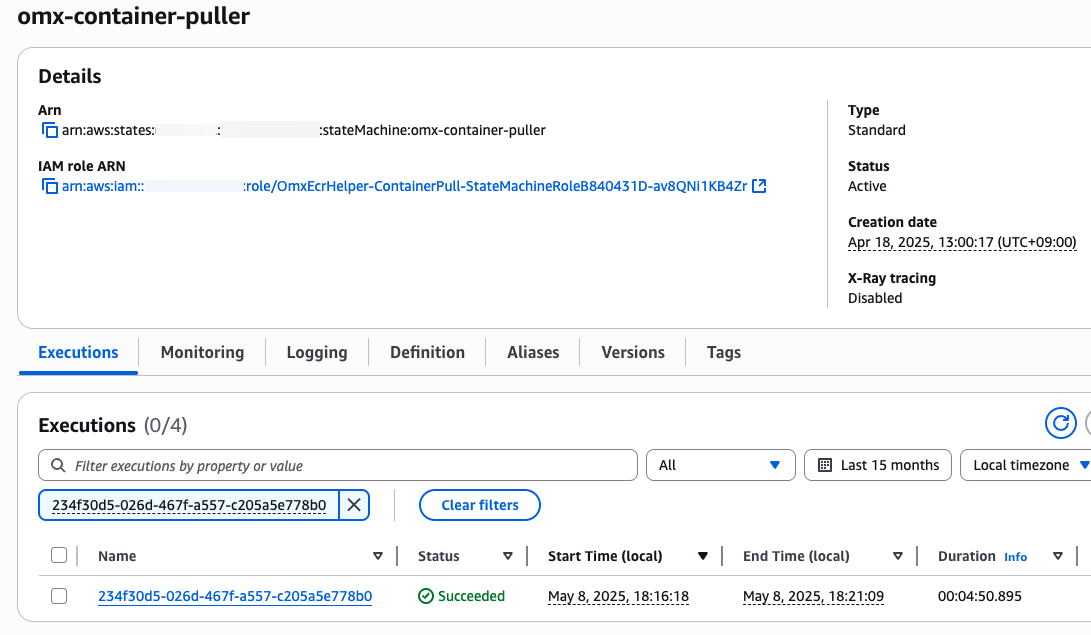
aws stepfunctions start-execution \
--state-machine-arn arn:aws:states:$region:$your_account_id:stateMachine:omx-container-puller \
--input file://scrnaseq_271_docker_images_manifest.spatialvi_dev_docker_images_manifest.json
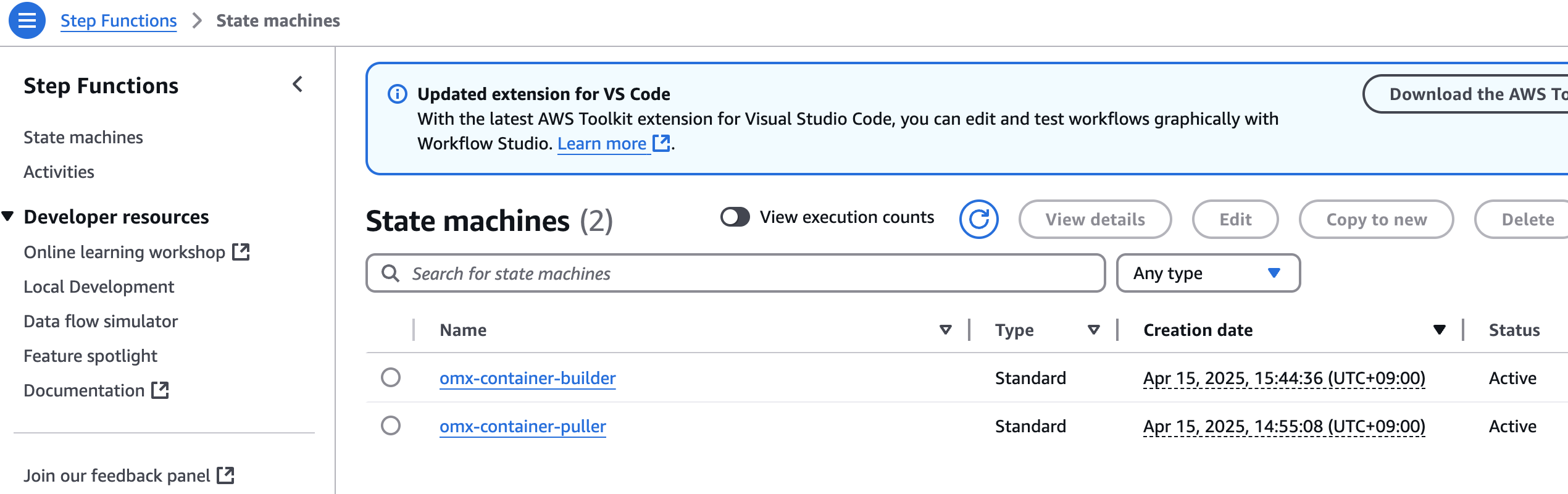
step function 콘솔에서 state machines중에 omx-container-puller를 확인하여 Execution이 완료되었는지 확인합니다.
nf-core project 코드 업데이트
To use the newly migrated containers for our workflow, copy the omics.config generated from inspect_nf.py in the /conf dir of the scrnaseq project.
mv omics.config scrnaseq/conf
Update the nextflow.config file in the root dir of the scrnaseq project by adding to the bottom of the file:
echo "includeConfig 'conf/omics.config'" >> scrnaseq/spatialvi/nextflow.config AWS신규 HealthOmics 워크플로우 만들기
단계1. AWS HealthOmics 파라미터 파일
parameter-description.json을 만들어 아래와 같이 저장합니다.
cat << EOF > parameter-description.json <<EOF
{
"input":{
{"description":"CSV "Samplesheetsamplesheet withcontaining sample locations."information",
"optional":false
false}},
"protocol"spaceranger_probeset":{
: {"description":"Probe "10Xset Protocolfile used:for 10XV1,Space 10XV2,Ranger 10XV3"analysis",
"optional":false
false}},
"aligner"spaceranger_reference":{
{"description":"Reference "choicegenome oftarball aligner:for alevin,Space star, kallisto"Ranger",
"optional":false
false}},
"barcode_whitelist"qc_min_counts":{
{"description":"Minimum "Optionalcount whitelistthreshold iffor 10XQC protocol is not used."filtering",
"optional":true
true}},
"gtf"qc_min_genes":{
{"description":"Minimum "S3number pathof togenes GTFthreshold file"for QC filtering",
"optional":true
false},
"fasta": {"description": "S3 path to FASTA file",
"optional": false},
"skip_emptydrops": {"description": "module does not work on small dataset",
"optional": true}}
}
EOF단계2. 워크플로우 스테이징
zip -r scrnaseq-workflow.spatialvi.zip scrnaseqspatialvi/ -x "*/\.*" "*/\.*/**"
aws s3 cp scrnaseq-workflow.spatialvi.zip s3://${yourbucket}/workshop/scrnaseq-workflow.spatialvi.zip
aws omics create-workflow \
--name ${workflow_name} \
--definition-uri s3://${yourbucket}/workshop/scrnaseq-spatialvi-workflow.zip \
--parameter-template file://parameter-description.json \
--engine NEXTFLOW
단계3. 워크플로우 생성 확인
workflow_id=$(aws omics list-workflows --name ${workflow_name} --query 'items[0].id' --output text)
echo $workflow_id워크플로우 테스트하기
작은 크기의 예제 샘플
입력파일 준비
parameter-description.json에 사용된 것과 동일한 키를 사용하여 input.json 파일을 새로 만듭니다. 값은 워크플로에서 허용되는 실제 S3 경로 또는 문자열이 됩니다.
아래는 테스트 샘플의 파라미터 예시입니다. (참고)
데이터 준비 참고
예제 데이터는 다음과 같이 다운로드 해볼 수 있습니다.
wget "https://github.raw.githubusercontent.com/nf-core/test-datasets/raw/scrnaseq/samplesheet-spatialvi/testdata/human-brain-cancer-11-mm-capture-area-ffpe-2-0.csvstandard_v2_ffpe_cytassist/samplesheet_spaceranger.csv"
wget "https://github.raw.githubusercontent.com/nf-core/test-datasets/raw/scrnaseq/reference/GRCm38.p6.genome.chr19.faspatialvi/testdata/human-brain-cancer-11-mm-capture-area-ffpe-2-standard_v2_ffpe_cytassist/outs/probe_set.csv"
wget "https://github.raw.githubusercontent.com/nf-core/test-datasets/raw/scrnaseq/reference/gencode.vM19.annotation.chr19.gtfspatialvi/testdata/homo_sapiens_chr22_reference.tar.gz"이제 현재 디렉토리에 다운로드 된 파일들을 버킷에 업로드할 수 있습니다.
aws s3 syncmv .samplesheet_spaceranger.csv s3://omics-output-us-east-1-462922227709/workflow_migration_workshop/nfcore-scrnaseq-v4.0.0/${yourbucket}/spatialvi/
aws s3 mv probe_set.csv s3://${yourbucket}/spatialvi/
aws s3 mv homo_sapiens_chr22_reference.tar.gz s3://${yourbucket}/spatialvi/sample sheet 만들기
cat << EOF > samplesheet-2-0.samplesheet_spaceranger.csv
sample,fastq_1,fastq_2,expected_cells,seq_centerfastq_dir,cytaimage,slide,area,manual_alignment,slidefile
Sample_X,CytAssist_11mm_FFPE_Human_Glioblastoma_2,s3://aws-genomics-static-${region}bucket}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/Sample_X_S1_L001_R1_001.fastq.spatialvi/fastq_dir.tar.gz,s3://aws-genomics-static-${region}bucket}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/Sample_X_S1_L001_R2_001.fastq.gz,5000,"Broad Institute"
Sample_Y,spatialvi/CytAssist_11mm_FFPE_Human_Glioblastoma_image.tif,V52Y10-317,B1,,s3://aws-genomics-static-${region}bucket}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/Sample_Y_S1_L001_R1_001.fastq.gz,s3://aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/Sample_Y_S1_L001_R2_001.fastq.gz,5000,"CRG Barcelona"
Sample_Y,s3://aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/Sample_Y_S1_L002_R1_001.fastq.gz,s3://aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/Sample_Y_S1_L002_R2_001.fastq.gz,5000,"CRG Barcelona"spatialvi/V52Y10-317.gpr
EOF위에서 만든 samplesheet를 s3로 복사
aws s3 cp samplesheet-2-0.samplesheet_spaceranger.csv s3://${yourbucket}/nfcore-scrnaseq/samplesheet-2-0.csv입력 json 만들기 (위 sample sheet경로가 아래 내용중 input에 값으로 들어가게됨)
cat << EOF > input.json
{
"input": "s3://${yourbucket}/nfcore-scrnaseq/samplesheet-2-0.csv",
"protocol": "10XV2",
"aligner": "star",
"fasta": "s3://aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/GRCm38.p6.genome.chr19.fa",
"gtf": "s3://aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/gencode.vM19.annotation.chr19.gtf",
"skip_emptydrops": true
}
EOF실제 크기의 샘플
(출처: 참고)
데이터 내 버킷내에 준비
aws s3 sync s3://ngi-igenomes/test-data/scrnaseq/ s3://${yourbucket}/test-data/scrnaseq/ --exclude "*" --include "pbmc8k_S1_L00*"
sample sheet 만들기
cat << EOF > samplesheet_2.0_full.csv
sample,fastq_1,fastq_2,expected_cells
pbmc8k,s3://${yourbucket}/test-data/scrnaseq/pbmc8k_S1_L007_R1_001.fastq.gz,s3://${yourbucket}/test-data/scrnaseq/pbmc8k_S1_L007_R2_001.fastq.gz,10000
pbmc8k,s3://${yourbucket}/test-data/scrnaseq/pbmc8k_S1_L008_R1_001.fastq.gz,s3://${yourbucket}/test-data/scrnaseq/pbmc8k_S1_L008_R2_001.fastq.gz,10000
EOF위에서 만든 samplesheet를 s3로 복사
aws s3 cp samplesheet_2.0_full.csv s3://${yourbucket}/nfcore-scrnaseq/samplesheet_2.0_full.spatialvi/samplesheet_spaceranger.csv입력 json 만들기 (위 sample sheet경로가 아래 내용중 input에 값으로 들어가게됨)
cat > input.json << EOF > input_full.json
{
"input": "s3://${yourbucket}/nfcore-scrnaseq/samplesheet_2.0_full.spatialvi/samplesheet_spaceranger.csv",
"protocol": "10XV2",
"aligner": "star",
"fasta"spaceranger_probeset": "s3://aws-genomics-static-${region}yourbucket}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/GRCm38.p6.genome.chr19.fa"spatialvi/probe_set.csv",
"gtf"spaceranger_reference": "s3://aws-genomics-static-${region}yourbucket}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/gencode.vM19.annotation.chr19.gtf"spatialvi/homo_sapiens_chr22_reference.tar.gz",
"skip_emptydrops"qc_min_counts": true5,
"qc_min_genes": 3
}
EOFPolicy 준비
Prepare IAM service role to run AWS HealthOmics workflow
your-bucket-name, your-account-id, your-region을 모두 본인 환경에 맞게 수정하여 사용하세요.
omics_workflow_policy.json 만들기
cat << EOF > omics_workflow_policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::${yourbucket}/*",
"arn:aws:s3:::aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::${yourbucket}",
"arn:aws:s3:::aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0",
"arn:aws:s3:::aws-genomics-static-${region}/workflow_migration_workshop/nfcore-scrnaseq-v2.3.0/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::${yourbucket}/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:DescribeLogStreams",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:${region}:${your_account_id}:log-group:/aws/omics/WorkflowLog:log-stream:*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup"
],
"Resource": [
"arn:aws:logs:${region}:${your_account_id}:log-group:/aws/omics/WorkflowLog:*"
]
},
{
"Effect": "Allow",
"Action": [
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchCheckLayerAvailability"
],
"Resource": [
"arn:aws:ecr:${region}:${your_account_id}:repository/*"
]
}
]
}
EOF
echo "omics_workflow_policy.json 파일이 생성되었습니다."trust_policy.json 만들기
cat << EOF > trust_policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "omics.amazonaws.com"
},
"Action": "sts:AssumeRole",
"Condition": {
"StringEquals": {
"aws:SourceAccount": "${your_account_id}"
},
"ArnLike": {
"aws:SourceArn": "arn:aws:omics:${region}:${your_account_id}:run/*"
}
}
}
]
}
EOF
echo "trust_policy.json 파일이 생성되었습니다."IAM Role 생성
aws iam create-role --role-name ${omics_role_name} --assume-role-policy-document file://trust_policy.json
Policy document 생성
aws iam put-role-policy --role-name ${omics_role_name} --policy-name OmicsWorkflowV1 --policy-document file://omics_workflow_policy.json
워크플로우 실행
작은 샘플의 예제는 input.json, 큰 샘플의 예제는 input_full.json
aws omics start-run \
--name scrnaseq_workshop_test_run_1spatialvi_test_run_1 \
--role-arn arn:aws:iam::${your_account_id}:role/${omics_role_name}\
--workflow-id ${workflow_id} \
--parameters file://input.json \
--output-uri s3://${yourbucket}/output/